
本記事では、2021年にあのOpenAIによって発表された画像とテキストのマルチモーダルな機械学習モデルであるCLIPについて解説していきます。CLIPには、近年のトレンドにもなっているマルチモーダルや、基盤モデルなどの要素を含んでおり、初学者がそれらの要素を理解するのに、とても良い実例だとわたくしは感じています。今日は難しい内容はできるだけ省き、CLIPの特徴や仕組み、仕様について解説していきます。
CLIPとは?
CLIPとはOpenAIが2021年に発表したモデルの1つで以下のような特徴を持っています。まずは細かい話に入る前に、それぞれの要素について簡単に触れておきます。
- マルチモーダルな機械学習モデル
- 基盤モデル
- ゼロショットラーニング
マルチモーダルな機械学習モデル
マルチモーダルとは、複数の異なる情報の種類を統合して処理することを総称します。機械学習などの分野で使われる概念で、テキスト、画像、音声、動画、さらにはセンサーデータなど、さまざまなデータを組み合わせて理解・生成することを指します。今回登場するCLIPは画像と、テキストのデータを入力にしたモデルであることから、マルチモーダルな機械学習モデルであると言えます。
基盤モデル
基盤モデルとは、FoundationModelとも呼ばれ、大規模なデータを用いて事前学習された汎用的な機械学習モデルのことです。これらのモデルは、さまざまなタスクに適応できるように設計され、ファインチューニング等で特定の用途に特化させることができます。CLIPは実に4億枚の画像とテキストのペアを用いて学習をしており、基盤モデルのひとつと言えます。
ゼロショットラーニング
ゼロショットラーニングとは、学習データに含まれていないようなデータについて、推論・分類等を行うタスクを指します。例えば、一般的な物体検出などの機械学習モデルは、検出する対象が決まっており、それらを学習することで、その対象を検出できるようにしますが、その場合学習データに含まれていないようなターゲットは検出することは難しいです。例えば、犬のデータだけを学習させた検出器では、鳥を検出することは難しい、というようなことです。ゼロショットラーニングでは、このような学習データに含まれていないような対象も検出するように学習を行います。CLIPにおいても、未知のデータに対して適切なスコアが出るような学習がなされています。
CLIPの仕様
では、そもそもCLIPとはどのようなモデルなのでしょうか?入出力を見てみるとイメージしやすいかと思います。
- 入力1:画像
- 入力2:テキストのリスト
- 出力:各テキストと画像のスコア
以下、実際に公式論文の図を見ながら理解をしていきましょう。
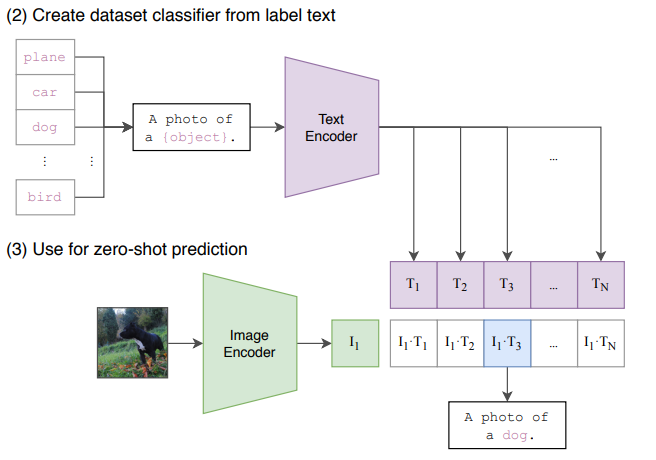
上記図の場合、入力は犬の画像と、N個のテキストの文字列になります。テキストの例としては[A photo of a plane, A photo of a car, A photo of a dog, ...]というように、文字列のリストが入力になっています。それぞれの入力は特徴抽出器(上記Encoder)に入れられ、特徴ベクトルに変換されます。そしてその出力の内積を取り、コサイン類似度を計算することで、それぞれのテキストと画像の類似度を1.0 から -1.0のスコアで出力します。これが基本的なCLIPの仕様になります。
上記のように特徴ベクトルのコサイン類似度を取るという非常にシンプルなロジックでありながらも、大規模なデータセット用いた基盤モデルとすることで未知のデータに対しても適切な類似度を算出できるような機械学習モデルが構築されています。
コサイン類似度とは、ベクトル間の類似度を表す指標の1つになります。ベクトルが全く異なる方向を向いている場合は-1.0、ベクトルが全く同じ方向である場合は1.0となります。基本的には2つのベクトルがなす角度のコサインの値を求めることになるため、コサインの取りうる値の範囲がそのまま類似度の尺度となります。
CLIPの学習の仕組み
入出力がわかったところで、CLIPの学習の仕組みを見てみましょう。以下が公式論文から引用した学習の概念図になります。
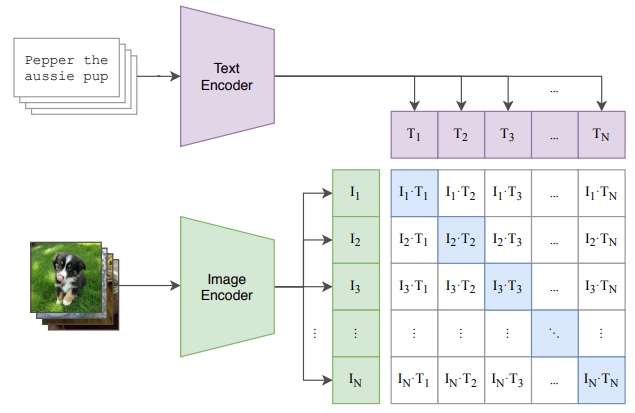
基本的には、画像とその中身を説明したテキストのペアを用意して、上記Encoderとなっている特徴抽出器を学習させていきますが、重要なポイントは、右側のマトリックスの部分です。これは、すべての画像とテキストのコサイン類似度を計算したマトリックスになっており、正しい画像とテキストのペアの類似度が対角成分(上記青色部)に来るように、配置計算をします。
つまり、対角成分にある組み合わせはすべてPositiveなデータとして、それ以外はNegativeなデータ(異なった組み合わせであるため)として考えれるため、この考え方とマトリックスを元に、特徴抽出器の学習します。
まとめ
今日はゼロショットなマルチモーダルな機械学習モデルであるCLIPについて、簡単に解説しました。CLIPは今や画像とテキストのクロスモーダルの基本形となっており、最近のモデルなどにおいてもこの思想が活用されています。HaggingFaceなどにもモデルがありますので、いろいろ試してみると面白いですよ!
参考
論文:https://arxiv.org/pdf/2103.00020
日本語解説記事(エクサウィザーズ様のテックブログより):https://techblog.exawizards.com/entry/2022/05/13/112049