
画像認識において、CNN(Convolutional Neural Network)とTransformer(特に本記事ではVision Transformerを扱います)は、今や2大手法といっても過言ではないと思います。ただ画像認識系の深層学習を始めたばかりだと基本的な文献はCNNベースの解説が多く、いざViTの概念を学ぼうとすると、手法の違いに戸惑いなかなか学習が進まない方も多いのではないでしょうか?今日は初学者向けにCNNとTransformerの特徴や違い等を解説したいと思います。
CNNとは?
CNNとはConvolution Neural Networkの略で、日本語では畳み込みニューラルネットワークと呼ばれています。これはフィルタ(またはカーネル)と呼ばれる画像の局所的な特徴を強調させるパラメータを用いて、畳み込み処理と呼ばれる内積演算を繰り返し行うことで、画像内におけるパターンを見つける手法になっています。
CNNを用いた機械学習における学習とは、このフィルタに設定されているパラメータの値(重みとも言います)を最適化することを指します。このパラメータを学習によって求めることで、画像内において検出や識別したい対象を抽出するフィルタを得ることができます。
Transformer(Vision Transformer)とは?
Transformerはもともと自然言語処理分野を席巻した深層学習のアーキテクチャの1つになります。近年では、Transformerのテクニックは画像認識の分野に拡張され、VisionToransformerと呼ばれるようになりました。
上記で説明したCNNは局所的な特徴を抽出する畳み込み処理は行わず、下図のようにパッチ分割された画像を入力にして、self-AttenstionやMLPと呼ばれる演算を行い、各パッチ間の関係性をとらえることが可能になります。
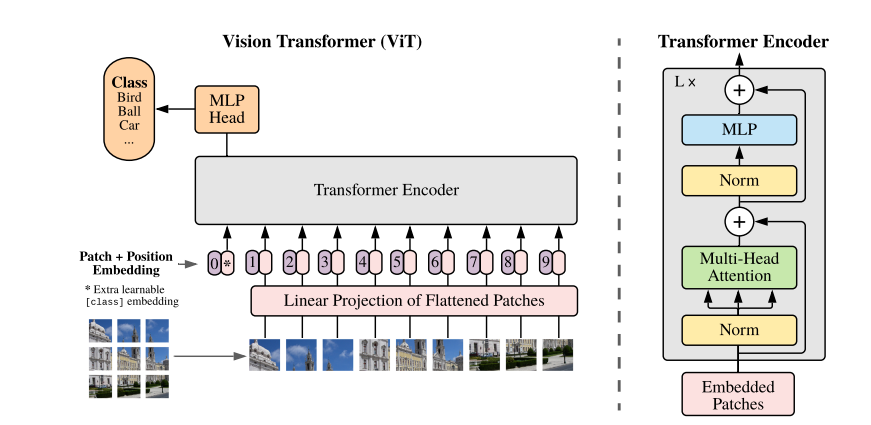
特徴
ではCNNとTransformerで、どのような特徴や違いがあるのでしょうか?
性能的なところはもちろんあるとは思いますが、一般的には得意とする受容野(認識をするのに使う範囲、目に置き換えるといわゆる見えている範囲)の違いや、処理速度的な部分が良く挙がります。
CNNの特徴
狭い範囲の特徴をとらえるのが得意
CNNは、特徴を抽出するフィルタを局所的に適用し、その特徴の組み合わせから認識を行うため、狭い範囲での認識が得意になります。なので、逆に言えばその受容野内での認識にとどまるため、大域的なシーンも取り込んでの認識などは苦手になります。
処理が軽い
これはCNNのアーキテクチャや入力解像度にも依存しますが、Transformerと比べると処理はシンプルで、学習や推論が比較的高速です。また少ないデータセットでも高い性能を出すことが可能と言われています。
Transformer(ViT)の特徴
広い範囲の特徴をとらえるのが得意
Transformerでは、各パッチ画像ごとの相関関係を考慮した特徴抽出を行うため、大域的な情報を見て認識することが可能になります。逆に各パッチないよりも小さい特徴などをとらえるのは苦手になります。
性能が高いが、処理が重い
一般的には大量のデータを用意できればTransformerは高い性能を出すことができます。ただし、億オーダーのデータセットが必要になることや、学習・推論に時間がかかるため、CNNよりは難度が高いとされています。ただ転移学習と相性が良いことから、事前学習済みの重みを転移学習することなどが可能なため、データの問題などはある程度解決することができます。
このようにCNNとTransformerでは特徴抽出方法の違いから、得手不得手があり、一長一短あるようなものになっています。
近年の動向
このようなメリットデメリットが大きくあるCNNとTransformerですが、これらを組み合わせて弱点を補うアーキテクチャも出始めています。
- CNNで特徴抽出をあらかじめ行いノイズ低減を行ったうえで、ViTでエンコードするアーキテクチャ
- Transformerの受容野を限定することで高速化を狙ったアーキテクチャ
- Swin-Transformer:https://arxiv.org/pdf/2103.14030
これらは一部にすぎませんが、CNNやViTが出てから結構経っていることもあって、弱点を補うような提案が行われており、実際のプロダクトへの適用も増えてきているように思います。
まとめ
今回はCNNとTransfomer、特にVisionTransfomer特徴について簡単に解説をしました。これはあくまでも単体の技術としての特徴になりますので、発展的なアーキテクチャでは、これらを解決しようとする動きがすでにあることを理解しつつ、細かいアーキテクチャなどについて、触れてみてはいかがでしょうか?
参考リンク
- ViT原著論文:https://arxiv.org/pdf/2010.11929