
Vision Transformer(ViT)は、画像認識の分野にTransformerの力を持ち込んだ革新的なアーキテクチャとして注目を集めています。その中でも、画像を小さなパッチに分割して処理するという独特な前処理が特徴です。従来は複雑なテンソル操作が必要だったこのステップを、PyTorchでは驚くほどシンプルに Conv2d を使って実現できます。CNNを使わないはずのTransformerでなぜこのようなことが可能なのか、図解をしてみたいと思います。
Vision Transformerとは?
Vision Transformerとは、自然言語の分野で使われていたTransformerというテクニックを画像認識分野に応用したアーキテクチャになります。CNNとは大きく異なる手法ながらも高性能を達成し、話題になりました。以下の記事で主だった特徴や、CNNとの違いについて解説していますので、大枠を知りたい方はそちらを参照してください。

Vision Transformer (ViT)の入力について
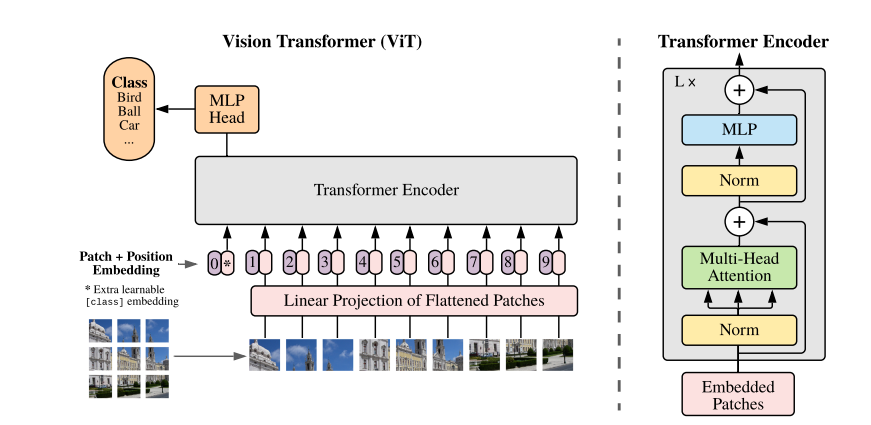
Vision Transformerでは、以下の順序で入力を作成し、上図の灰色のTransformer Encoderへのインプットを作成しています。
- 画像をパッチに分割 (上記では3x3のパッチ画像に分割)
- 各パッチをベクトルに変換(埋め込み:上図のLiner Projectionの部分)
- 各画像パッチ(RGBだと(3, h, w)の3次元が多い)を1次元の平たいベクトルに変換します。
- 位置埋め込みとCLSトークンの追加
- Transformerは順序を持たないため、各パッチに「どこにあるか」を示す位置情報を加えます。
- 分類タスクでは、全体の特徴を集約するための「CLSトークン」を先頭に追加します。
- Transformerに入力
- 最終的に、パッチ+位置情報+CLSトークンをTransformerに渡して処理します。
本記事で注目したいのが上記の1,2にあたる部分で、画像をパッチに分割することと、1次元へのベクトル変換についてです。
パッチ分割と埋め込みの実装
実際のパッチ分割と埋め込みの実装を見てみましょう。
RGBの画像を3x3のパッチ画像に分割して、128の1次元ベクトルに変換したいと仮定すると、以下のように実装を書くことができます。
img_size = 81 # (3, 81, 81)
in_channel = 3
emb_dim = 128
patch_size_row = 3 # pathc num: 3 * 3 = 9
patch_size = img_size // patch_size_row # 27
self.patch_embed = nn.Conv2d(
in_channels=in_channel,
out_channels=emb_dim,
kernel_size=patch_size,
stride=patch_size,
)なんとtorchのConv2dを用いて、先ほどの複雑な処理が1行で実装できてしまうということになります。
上記実装を図解してみる
上記実装がコードだとよくわからない部分もあるので、図を書いてみることにします。
入出力
上記コードをベースに入力と出力を図示すると、以下のようになります。左側が入力になるRGB画像(3, 81, 81)、右側がConv2dを使ってパッチ分割とベクトル化された出力になります。わかりやすいようにブロックに分割して図示していますが、それぞれのブロックが1x1x128の1次元のベクトルに変換されていることがわかると思います。
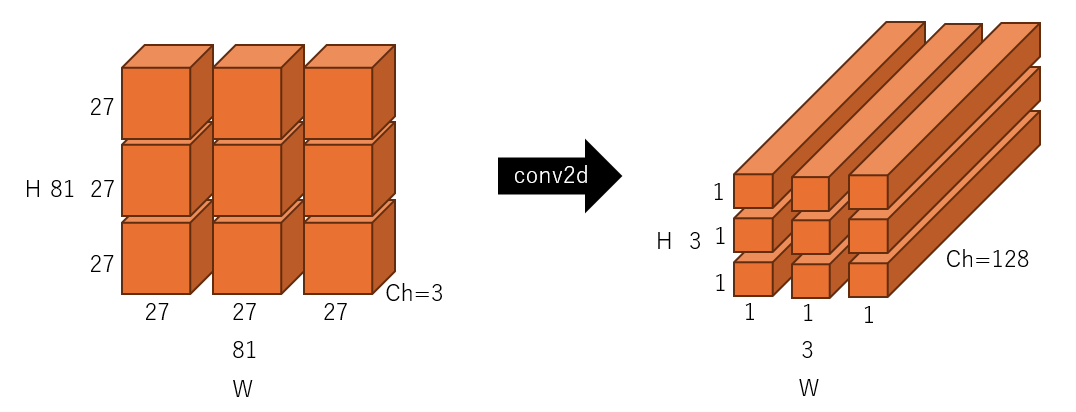
Conv2dでのパッチ分割における入出力の関係実際の動き
それでは実際の動きがどのようになるか図示してみましょう。
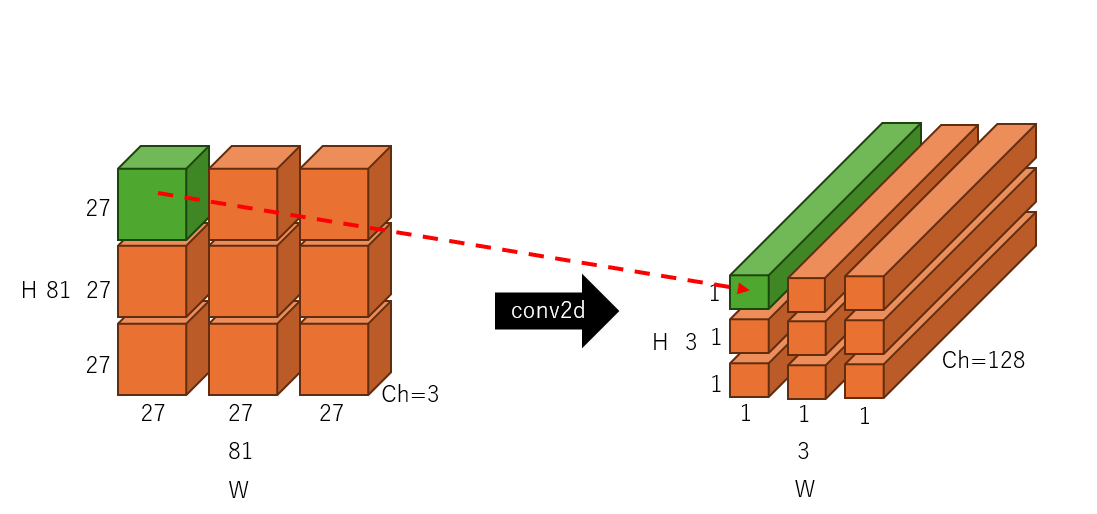
まずフィルターサイズが27 x 27のパッチ1個分のサイズになりますので、下の図の緑色の入力部分に畳み込み処理を適用します。この時出力チャネルが128になりますので、1回の畳み込みで1x1x128のベクトルが生成できるわけです。赤い点線矢印がその流れを示しています。
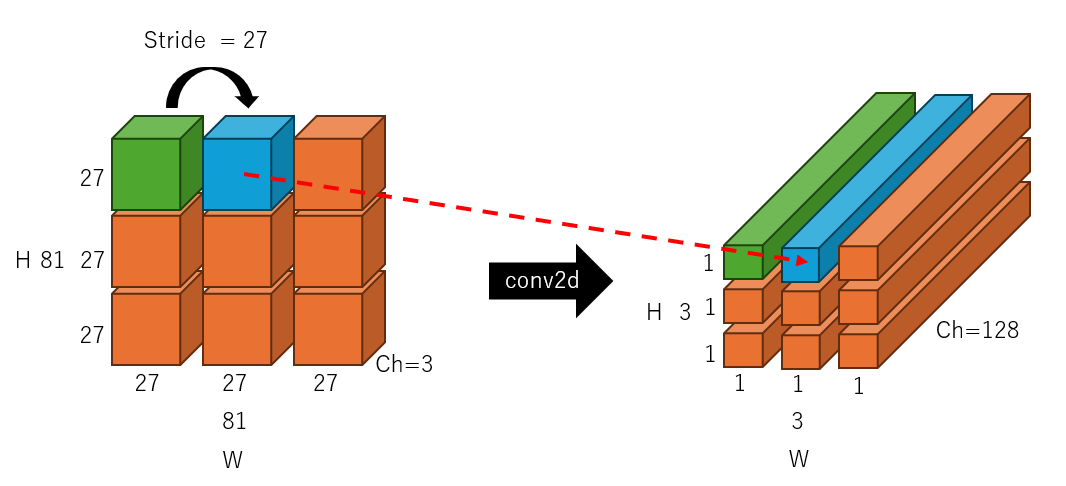
この畳み込みを1つの処理として次の畳み込みに移ります。この時ストライドがパッチのサイズと同じだけ、つまり27になっているため、次に処理されるのは、下記の図の青色のブロックになるわけです。ここまでくればあとはこの繰り返しで、入力の画像を分割しつつ、1次元のベクトルに変換できていることがわかります。Conv2dに与える引数を工夫することで、簡単に実装ができるということが理解できました。
まとめ
Vision Transformerのパッチ分割と埋め込み(ベクトル化)の実装について、図解してみました。Conv2dを利用することで簡単に実装できるというのは概念、言葉としては理解できていたものの、なぜできるのか?というのを深堀できていなかったのですが、こうやって自分で図示することで、理解を深めることができて非常に有意義でした。